수학적인 함수, 수학적인 계산 담당
- 넘파이 배열과 리스트의 차이점
- 넘파이가 제공하는 다차원 배열 넘파이의 강력한 기능을 직접 사용하면서 익히기
- 확률 분포와 난수 생성.
- 고차원 배열의 인덱싱 기법
- 넘파이가 제공하는 데이터 분석 함수 사용
- 다수 변수들 간의 상관관계 계산
리스트, 넘파이배열(nd.array)
리스트는 여러 개의 값들을 저장할 수 있는 자료구조.
리스트는 다양한 자료형의 데이터를 여러 개 저장할 수 있으며 데이터를 변경하거나 추가, 제거할 수 있음.
하지만 데이터 과학에서는 파이썬의 기본 리스트로 충분하지 않음.
데이터를 처리할 떄는 리스트와 리스트 간의 다양한 연산이 필요함.
따라서, 데이터 과학자들은 기본 리스트 대신에 넘파이 선호
Numpy란.
- numpy는 C언어로 구현된 파이썬 라이브러리로써,고성능의 수치계산을 위해 제작. 먼저, numpy를 이용하기 위해서는 numpy를 import 해야 함.
import numpy as npnumpy 기초
# numpy 사용.
import numpy as np# Array 정의.
data1 = [1,2,3,4,5]
data1
data2 = [1,2,3,3.5,4]
data2
# numpy를 이용하여 array 정의.
# 1. 위에서 만든 python list를 이용.
arr1 = np.array(data1)
arr1
# array의 형태(크기)를 확인할 수 있음.
arr1.shape
# 2. 바로 python list를 넣어 줌으로써 만듦.
arr2 = np.array([1,2,3,4,5])
arr2
arr2.shape
# array의 자료형을 확인할 수 있음.
arr2.dtype
arr3 = np.array(data2)
arr3
arr3.shape
arr3.dtype
arr4 = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
arr4
arr4.shapenumpy shape
numpy에서는 해당 array의 크기를 알 수 있음. shape를 확인함으로써 몇개의 데이터가 있는지, 몇 차원으로 존재하는지 등을 확인할 수 있음. 위에서 arr1.shape의 결과는 (5,) 으로써, 1차원의 데이터이며 총 5라는 크기를 갖고 있음을 알 수 있음.
numpy 자료형
arr1이나 arr2는 int64라는 자료형을 갖는 것에 반해 arr3는 float64라는 자료형을 갖음. 이는 arr3 내부 데이터를 살펴보면 3.5라는 실수형 데이터를 갖기 때문임을 알 수 있음. numpy에서 사용되는 자료형은 아래와 같음. (자료형 뒤에 붙는 숫자는 몇 비트 크기인지를 의미)
- 부호가 있는 정수 int(8, 16, 32, 64)
- 부호가 없는 정수 unit(8, 16, 32, 64)
- 실수 float(16, 32, 64, 128)
- 복소수 complex(64, 128, 256)
- 불리언 bool
- 문자열 string_
- 파이썬 오브젝트 object
- 유니코드 unicode
넘파이의 핵심적인 객체는 다차원 배열
ex) 정수들의 2차원 배열(테이블)을 넘파이를 이용해서 생성.
배열의 각 요소는 인덱스(index)라고 불리는 정수들로 참조됨.
넘파이에서 차원은 축(axis)이라고도 함
- Why 넘파이?
- 넘파이는 성능이 우수한 ndarray 객체 제공.
- ndarray의 장점.
- ndarray는 C언어에 기반한 배열 구조 : 메모리를 적게 차지하고 속도가 빠름.
- ndarray를 사용하면 배열과 배열 간에 수학적인 연산을 적용할 수 있음.
- ndarray는 고급 연산자와 풍부한 함수들을 제공
Numpy의 장점
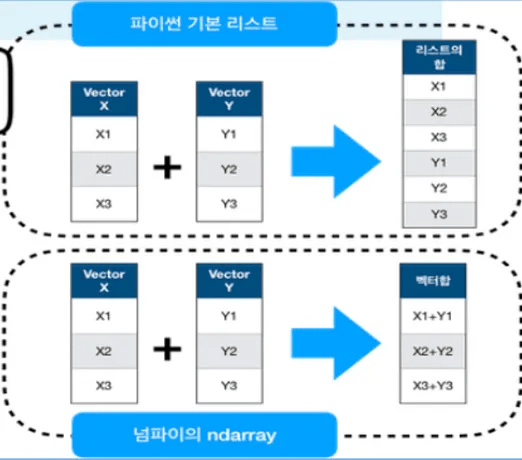
- 파이썬 리스트 더하기 연산자는 두 리스트를 연결
- Numpy배열 더하기 연산자는 벡터의 연산으로 계산
np.zeros(), np.ones(), np.arange() 함수
np.zeros(10)
np.zeros((3,5))
# np.ones() 함수는 인자로 받는 크기만큼, 모든요소가 1인 array를 만듦.
np.ones(9)
np.ones((2, 10))# np.arange() 함수는 인자로 받는 값 만큼 1씩 증가하는 1차원 array를 만듦.
# 이때, 하나의 인자만 입력하면 0~ 입력한 인자 값 만큼의 크기를 가짐.np.arange(10)
np.arange(3, 10)array 연산
기본적으로 numpy에서 연산을 할 때는 크기가 서로 동일한 array 끼리 연산이 진행됨.
arr1 = np.array([[1,2,3], [4,5,6]])
arr1arr1.shape
arr2 = np.array([[10, 11, 12], [13, 14, 15]])
arr2
arr2.shape
# array 덧셈
arr1 + arr2
# array 뺄셈.
arr1 - arr2
# array 곱셈.
arr1 * arr2
# array 나눗셈.
arr1 / arr2
# array의 브로드 캐스트.
# 위에서 array가 같은 크기를 가져야 사로 연산이 가능하다고 했지만,
# numpy에서는 브로드캐스트라는 기능을 제공.
# 브로드캐스트란?, 서로 크기가 다른 array가 연산이 가능하게 끔 하는 것.
arr1
arr1.shape
arr3 = np.array([10, 11, 12])
arr3
arr3.shape
arr1 + arr3
arr1 * arr3
arr1 * 10
# 각각의 데이터의 제곱처리
arr1 ** 2array 인덱싱
numpy에서 사용되는 인덱싱은 기본적으로 python 인덱싱과 동일. 이때, python에서와 같이 1번째 시작하는 것이 아니라 0번째로 시작하는 것에 주의해야 함.
import numpy as nparr1 = np.arange(10) # 0~9까지 숫자를 numpy배열에 표현이 됨.
arr1
# 1번째 데이터
arr1[0]
# 3번째 데이터
arr1[2]
# 4번째 요소부터 9번째 요소
arr1[3:9]
# 전체데이터를 뽑음
arr1[:]arr2 = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,12]])arr2# 2차원의 array에서 인덱싱을 하기 위해서는 2개의 인자를 입력해야 함.
arr2[0, 0]
# 3행의 모든 요소 꺼내기.
arr2[2, :]
# 3행의 4번째 요소 꺼내기.
arr2[2, 3]
# 모든 행, 열의 4번째 요소 꺼내기
arr2[:, 3]array boolean 인덱싱(마스크)
위에서 이용한 다차원의 인덱싱을 응용하여 boolean 인덱싱을 할 수 있음. 해당 기능은 주로 마스크라고 이야기하는데, boolean인덱싱을 통해 만들어낸 array를 통해 우리가 원하는 행 또는 열의 값만 뽑아낼 수 있음. 즉, 마스크처럼 우리가 가리고 싶은 부분은 가리고, 원하는 요소만 꺼낼 수 있음.
names = np.array(['Beomwoo','Beomwoo','Kim','Joan','Lee','Beomwoo','Park','Beomwoo'])
names
names.shape
# 아래에서 사용되는 np.random.randn() 함수는 기대값이 0이고, 표준편차가 1인 가우시안 정규 분포를 따르는 난수를 발생시키는 함수.
# 이 외에도 0~1의 난수를 발생시키는 np.random.rand() 함수도 존재함.
data = np.random.randn(8,4) # 가로(row) 8, 세로(col) 4 인 데이터 구조를 가지는 난수(랜덤한 숫자)를 생성해라.
data
data.shape위와 같은 names와 data라는 array가 있음. 이때, names의 각 요소가 data의 각 행과 연결된다고 가정해보자. 그리고 이 때, names가 Beomwoo인 행의 data만 보고 싶을 때 다음과 같이 마스크를 사용.
# 요소가 Beomwoo인 항목에 대한 mask 생성.
names_Beomwoo_mask = (names == 'Beomwoo')
names_Beomwoo_mask
data[names_Beomwoo_mask,:] # data[names == 'Beomwoo', :]
# 요소가 Kim인 행의 데이터만 꺼내기
data[names == 'Kim',:]
# 논리 연산을 응용하여, 요소가 Kim 또는 Park인 행의 데이터만 꺼내기
data[(names == 'Kim') | (names == 'Park'),:]
# 먼저 마스크를 만든다.
# data array에서 0번째 열이 0보다 작은 요소의 boolean 값은 다음과 같음.
data[:,0] < 0
# 위에서 만든 마스크를 이용하여 0번째 열의 값이 0보다 작은 행을 구함.
data[data[:,0]<0,:]이를 통해 특정 위치에만 우리가 원하는 값을 대입가능
# 0번째 열의 값이 0보다 작은 행의 2,3번째 열 값.
data[data[:,0]<0,2:4]
data[data[:,0]<0,2:4] = 0
dataNumpy 함수
arr1 = np.random.randn(5,3)
arr1
# 각 성분의 절대값 계산하기
np.abs(arr1)
# 각 성분의 제곱근 계산하기 ( == array ** 0.5)
np.sqrt(arr1)
# 각 성분의 제곱 계산하기
np.square(arr1)
# 각 성분을 무리수 e의 지수로 삼은 값을 계산하기
np.exp(arr1)
# 각 성분을 자연로그, 상용로그, 밑이 2인 로그를 씌운 값을 계산하기
np.log(arr1)
np.log10(arr1)
np.log2(arr1)
# 각 성분의 부호 계산하기(+인 경우 1, -인 경우 -1, 0인 경우 0)
np.sign(arr1)
# 각 성분의 부호 계산하기(+인 경우 1, -인 경우 -1, 0인 경우 0)
np.sign(arr1)
# 각 성분의 소수 첫 번째 자리에서 내림한 값을 계산하기
np.floor(arr1)
np.isnan(np.log(arr1))
# 각 성분이 무한대인 경우 True를, 아닌 경우 False를 반환하기
np.isinf(arr1)
# 각 성분에 대해 삼각함수 값을 계산하기(cos, cosh, sin, sinh, tan, tanh)
np.sin(arr1)두 개의 array에 적용되는 함수
arr1
arr2 = np.random.randn(5,3)
arr2
# 두 개의 array에 대해 동일한 위치의 성분끼리 연산 값을 계산하기
# (add, subtract, multiply, divide)
np.multiply(arr1,arr2)
# 두 개의 array에 대해 동일한 위치의 성분끼리 비교하여 최대값 또는 최소값 계산하기(maximum, minimum)
np.maximum(arr1,arr2)기본적인 통계함수
arr1
# 전체 성분의 합을 계산
np.sum(arr1)
# 행 간의 합을 계산
np.sum(arr1, axis=1)
# 열 간의 합을 계산
np.sum(arr1, axis=0)
# 전체 성분의 평균을 계산
np.mean(arr1)
# 행 간의 평균을 계산
np.mean(arr1, axis=0, 1)
# 전체 성분의 표준편차, 분산, 최소값, 최대값 계산(std, var, min, max)
np.std(arr1)
np.min(arr1, axis=0, 1)
# 전체 성분의 최소값, 최대값이 위치한 몇번째를 반환(argmin, argmax)
np.argmin(arr1)
np.argmax(arr1,axis=0, 1)
# 맨 처음 성분부터 각 성분까지의 누적합 또는 누적곱을 계산(cumsum, cumprod)
np.cumsum(arr1)
np.cumsum(arr1,axis=0, 1)
np.cumprod(arr1)Numpy에서의 인덱싱과 슬라이싱
scores = np.array([88,72,93,94,89,78,99])
scores[2]
scores[-1]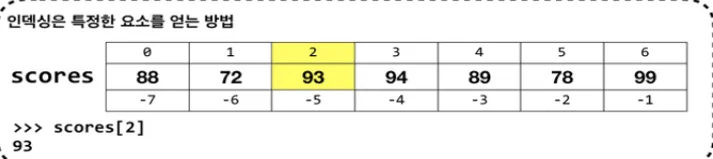

score[3:] # 마지막 인덱스를 생략하면 디폴트 값은 -1임
scores[4:-1] # 마지막 인덱스로 -1을 사용할 경우 -1의 앞에 있는 78까지 슬라이싱함.논리적인 인덱싱을 통한 값 추출
- 논리적인 인덱싱이란 어떤 조건을 주어서 배열에서 원하는 값을 추려내는 것
ages = np.array([18, 19, 25, 30, 28])- ages에서 20살 이상인 사람만 고르려고 하면 다음과 같은 조건식을 써줌
y = ages > 20
y # 결과는 부울형의 넘파이 배열.age[ages > 20]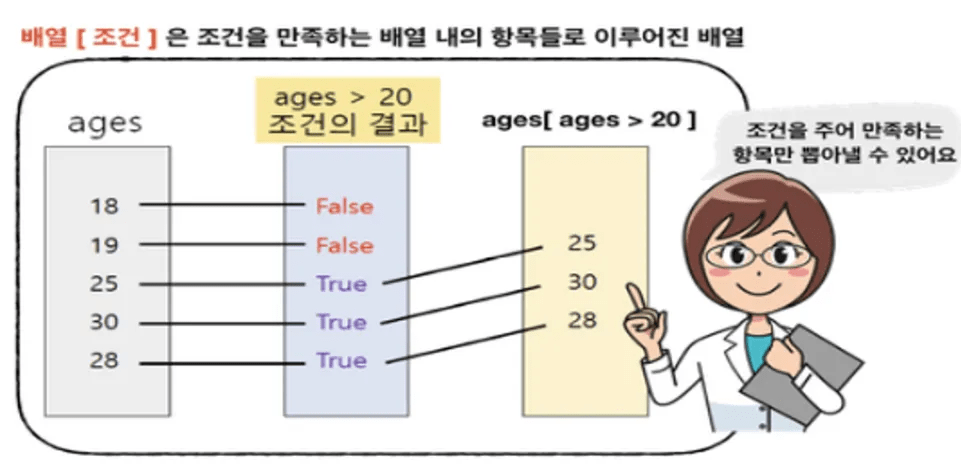
bmi = np_weights/(np_heights ** 2)
print(bmi[bmi > 25])2차원 배열의 인덱싱
- 2차원 리스트는 “리스트의 리스트”라고 말할 수 있음.
- 수학의 행렬과는 비슷하지만 리스트는 행렬 연산을 지원하지 않음.
import numpy as np
y = [[1,2,3],[4,5,6],[7,8,9]]
y- 넘파이의 2차원 배열은 수학에서의 행렬과 같이 다룰 수 있음.
-> 역행렬이나 행렬식을 구하는 등의 행렬 연산들이 쉽게 적용될 수 있음.
np_array = np.array(y)
np_array- 첫 번째 인덱스는 행, 두 번째 인덱스는 열
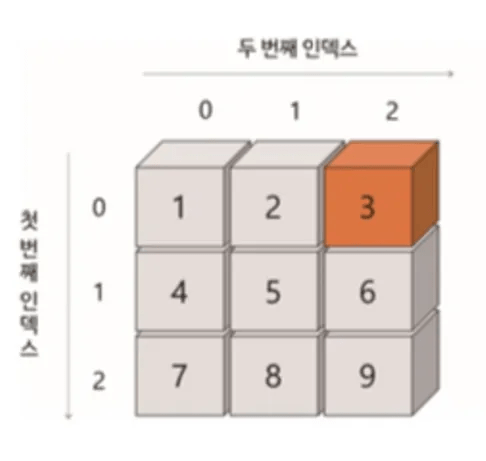
np_array[0][2]- np_array[0][1] == np_array[0,1](넘파이 표기법)
- 콤마 앞에 값은 행, 콤마 뒤에 값은 열
np_array[0, 0] = 12
np_array- 파이썬 리스트와 달리, 넘파이 배열은 모든 항목이 동일한 자료형을 가짐.
- 정수 배열에 부동 소수점 값을 삽입하려고 하면 소수점 이하값은 버림.
np_array[2,2] = 1.234
np_array- 슬라이싱은 큰 행렬에서 작은 행렬을 추출하는 의미
np_array = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16]])
np_array[0;2, 2:4]- 2차원 행렬에서 하나의 행을 지정하는 방식
np_array[0]- 넘파이 스타일의 표기법도 가능
np_array[1, 1:3]- ndarray의 인덱싱 및 슬라이싱 예제
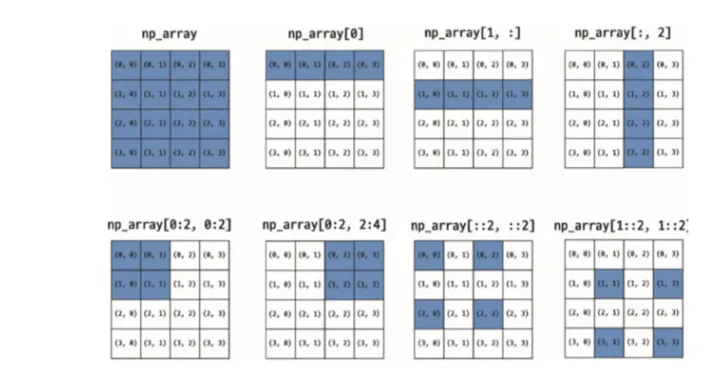
import numpy as np
np_array = np.array([[1,2,3], [4,5,6], [7,8,9]])
np_array > 5
np_array[np_array > 5]
np_array[:, 2]
np_array[:, 2] > 5
np_array[:] % 2 == 0
np_array[np_array % 2 == 0]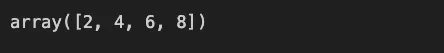
난수생성함수
함수내용np.random.seed()np.random.seed(42)np.random.randn()표준 정규분포에 따른 n개의 무작위 숫자 생성np.random.randint()np.random.randint(0, 10, 5) # 0 이상 10 미만의 숫자 5개 랜덤 생성
linspace() 함수, logspace() 함수
linspace()는 시작값부터 끝값까지 균일한 간격으로 지정된 개수만큼의 배열 생성.

비슷한 함수로 logspace()함수로 로그스케일로 수들을 생성

linspace() 함수와 logspace() 함수
np.linspace(0, 10, 100)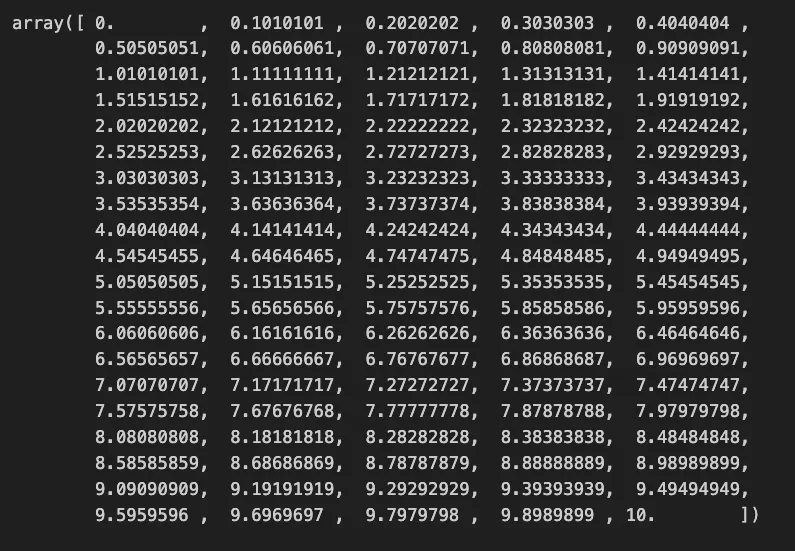
0부터 10까지 균일한 간격으로 100개로 쪼갬
np.logspace(0, 5, 10)
배열의 형태를 바꾸는 reshape() 함수, flatten() 함수
- reshape() 함수는 상당히 많이 사용되는 함수.
- 데이터의 개수는 유지한 채로 배열의 차원과 형태 변경. 이 함수의 인자인 shape를 튜플의 형태로 넘겨주는 것이 원칙이지만, reshape(x, y)라고 하면 reshape((x, y))와 동일하게 처리.
y = np.arange(12)
y
y.reshape(3, 4)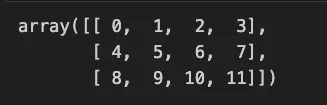
배열의 형태를 3행 4열 형태로 바꿔줌
y.reshape(6, -1)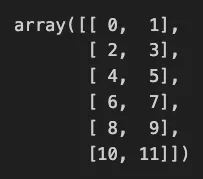
y.reshape(7, 2)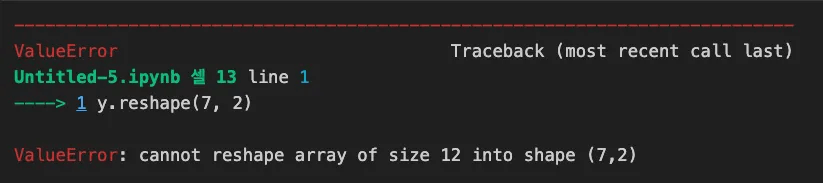
reshape()에 의해 생성될 배열의 형태가 호환되지 않을 경우 발생하는 오류
y.flatten() # 배열의 2차원이상의 고차원 배열을 1차원으로 작성하는 함수