회귀분석
flowchart TD
A['1단계 패키지 설정'] --> B['2단계 데이터 준비'] --> C['3단계 탐색적 데이터분석'] --> D['4단계 피처 스케일링'] --> E['5단계 모형화 및 학습'] --> F['6단계 예측']from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib.pyplot as plt# 학습용 데이터
# 입력.
X_train = np.array([[25, 25],
[33, 30],
[38, 30],
[45, 35],
[28, 40]])
# 라벨.
y_train = np.array([0,0,1,1,0])
# 테스트용 데이터(새로운 개체)
X_test = np.array([[30, 35]]) # 새로운 개체의 X1, X2
# 산포도.
# 학습용 데이터.
plt.scatter(X_train[:,0], X_train[:,1], c = y_train)
# 테스트용 데이터.
plt.scatter(X_test[:,0], X_test[:,1], c = 'red', marker = 'D', s = 100)
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()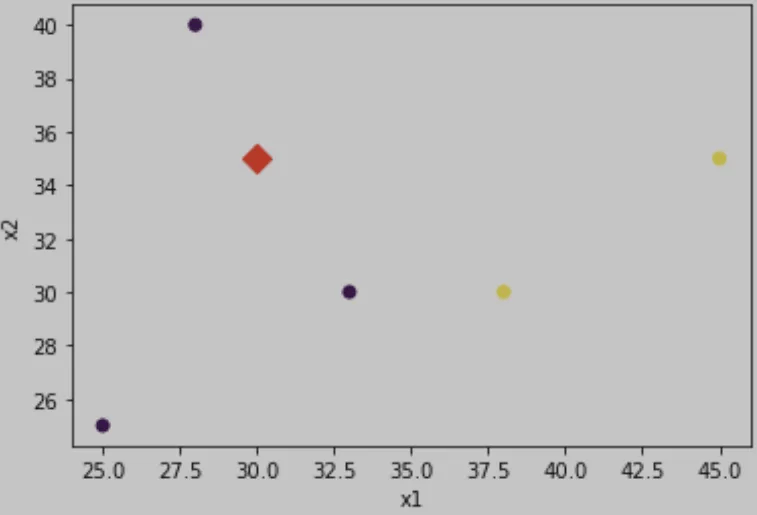
# 피처 스케일링: 학습용 데이터.
scalerX = StandardScaler()
scalerX.fit(X_train)
X_train_std = scalerX.transform(X_train)
print(X_train_std)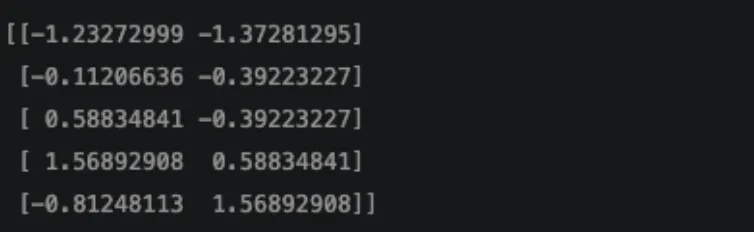
# 피처 스케일링 : 테스트용 데이터.
X_test_std = scalerX.transform(X_test)
print(X_test_std)
# 모형화.
knn = KNeighborsClassifier(n_neighbors=3, metric='euclidean')
# 학습.
knn.fit(X_train_std, y_train)
# 에측.
pred = knn.predict(X_test_std)
print(pred)
#클래스별 확률 값을 반환.
knn.predict_proba(X_test_std)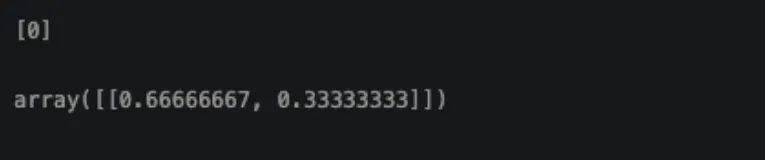
# 인접한 k개의 개체들에 대한 거리와 색인을 반환.
dist,index = knn.kneighbors(X_test_std)
print(dist)
print(index)
KNN(k-Nearest Neighbor Classifier)
K-NN의 꽃잎 분류에의 적용 예.
- 꽃잎의 크기와 밝기에 따른 K-NN 분류.
- 오른쪽 위에 새로운 꽃잎이 입력으로 들어왔을 때 빨간 화살표의 3가지를 비교한 후 분류하는 것을 보여줌.
K-NN의 장단점과 활용 분야.
- 장점은 매우 간단하며 빠르고 효과적인 알고리즘 또 어떤 데이터라도 유사성 측정 가능.
- 단점으로는 적절한 k를 선택해야 한다는 점 새로운 데이터에 대해 일일이 거리를 계산한 후 분류.
K-NN의 활용 분야.
- 영화나 음악 추천에 대한 개인별 선호 예측.
- 수표에 적힌 광학 숫자와 글자인식.
- 얼굴인식과 같은 컴퓨터 비전.
- 유방암 등 질병의 진단과 유전자 데이터 인식.
- 재정적인 위험성의 파악과 관리, 주식 시장 예측.
# 새로운 값을 분류할 때 .predict() 사용.
unknown_points = [
[0.2,0.1,0.7],
[0.4,0.7,0.6],
[0.5,0.8,0.1]
]guesses = classifier.predict(unknown_points)
print(guesses)
sklearn을 이용한 kNN 알고리즘 실습
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data)
# 4개의 특징 이름을 출력.
print(iris.feature_names)
# 정수는 꽃의 종류를 나타낸다.: 0 = setosa, 1 = versicolor, 2 = virginica
print(iris.target)
from sklearn.model_selection import train_test_splitX = iris.data
y = iris.target
# (80:20)으로 분할.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=4)
print(X_train.shape)
print(X_test.shape)from sklearn.neighbors import KNeighborsClassifier
from sklearn import metricsknn = KNeighborsClassifier(n_neighbors=6)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
scores = metrics.accuracy_score(y_test, y_pred)#0 = setosa, 1 = versicolor, 2 = virginca
classes = {0:'setosa', 1:'versicolor', 2:'virginca'}# 아직 보지 못한 새로운 데이터를 제시해보자.
x_new = [[3,4,5,2],
[5,4,2,2]]
y_predict = knn.predict(x_new)
print(classes[y_predict[0]])
print(classes[y_predict[1]])
나이브 베이지 분류 예제 살펴보기
나이브 베이즈의 정리
💡 P(A)가 A가 일어날 확률, P(B)가 B가 일어날 확률, P(B|A)가 A가 일어나고나서 B가 일어날 확률, P(A|B)가 B가 일어나고나서 A가 일어날 확률이라고 해봅시다. 이때 P(B|A) 를 쉽게 구할 수 있는 상황이라면, 아래와 같은 식을 통해 P(A|B)를 구할 수 있습니다.
P(A∣B)=P(B∣A)P(A)/P(B)
K-NN
- sklearn에서 제공하는 예시 데이터 중 유방암 데이터를 사용해 KNN 모델을 적용.
- KNeighborsClassifier(n_neighbos = K)에서 K를 1부터 100까지 변화시켜서 테스트 해보기.
- 가장 정확도가 큰 K는 얼마인지 알아보기.
