Email spam filter: labeled (spam or ham) 이메일로부터 학습
시험 점수 예측 : 이전의 시험 성적과 공부한 시간을 학습
Unsupervised learning
Unlabeled data로 학습.
어떤 데이터는 라벨을 일일이 할당할 수 없음
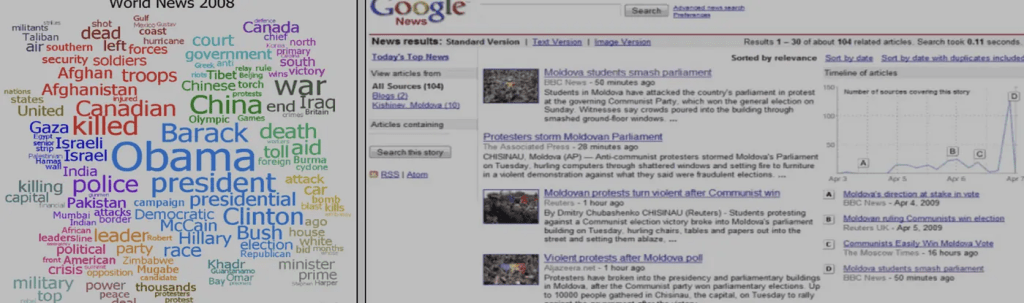
Google news grouping
자동적으로 유사한 뉴스를 그룹핑함
유사한 단어를 수집하는 Word clustering
일일이 데이터에 라벨을 부여하기가 어려움
데이터를 보고 스스로 학습을 수행
반지도학습.(semi-supervised learning.)
지도 학습과 비지도 학습의 중간에 위치함
입력과 출력 정보가 있는 학습데이터와 입력만 있고 출력 정보가 없는 학습데이터를 함꼐 사용함
입력과 출력정보가 함께 있는 학습데이터가 적은 상황에서 분류나 회귀 모델 개발시
출력 정보가 없는 입력데이터의 분포 특성 정보를 활용하여 성능 개선
강화학습(reinforcement learning.)
특정 환경에서 행동과 이에 대한 보상의 경험을 통해서 보상이 최대가 되도록 상황별로 취할 행동을 결정하는 방법
게임, 제어문제, 금융공학 등에서 행동 전략이나 정책을 결정할 때 사용함
supervised Learning의 수행단계
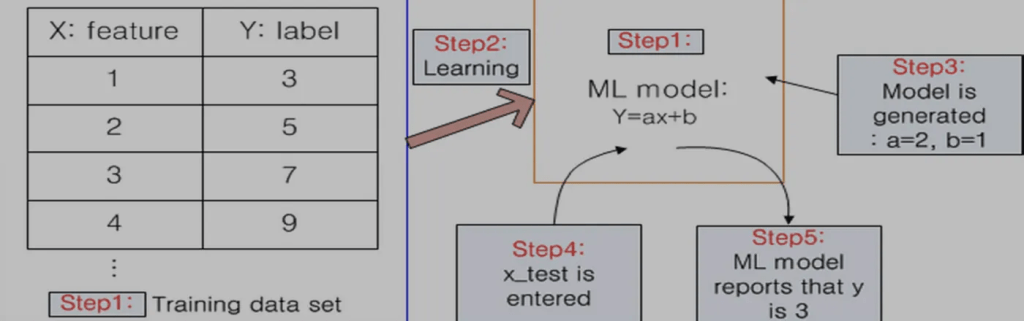
step 1 : Training data set과 ML 모델이 주어짐
step 2 : Label이 주어진 training data set을 학습시킴
step 3 : 학습을 통해 ML 모델이 생성됨
모델의 파라미터가 학습을 통해 결정됨
step 4 : 생성된 ML 모델에 x_test라는 값을 입력하여 y의 값을 물어봄
step 5 : 생성된 ML 모델은 x_test에 대한 y의 값은 3이라고 알려줌
감독학습의 종류.
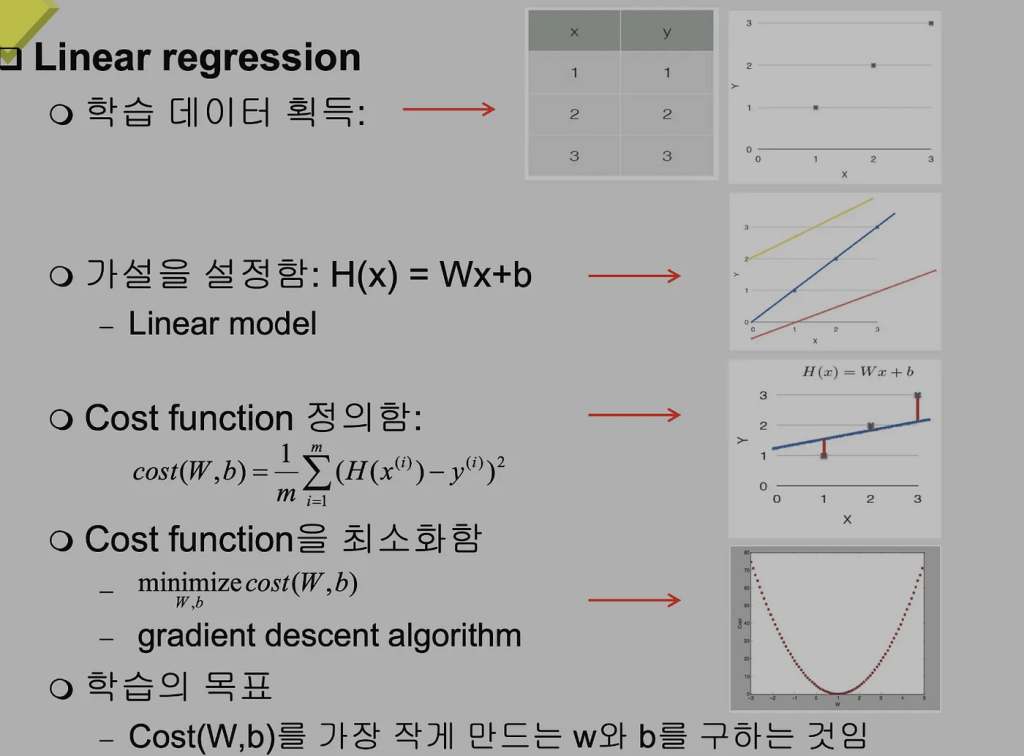
Regression
출력이 연속적인 영역 안의 값을 결정하는 분야
Linear regression과 nonlinear regression으로 분류됨
공부한 시간을 기반으로 0점에서 100점 사이의 시험 성적을 예측하는 시스템
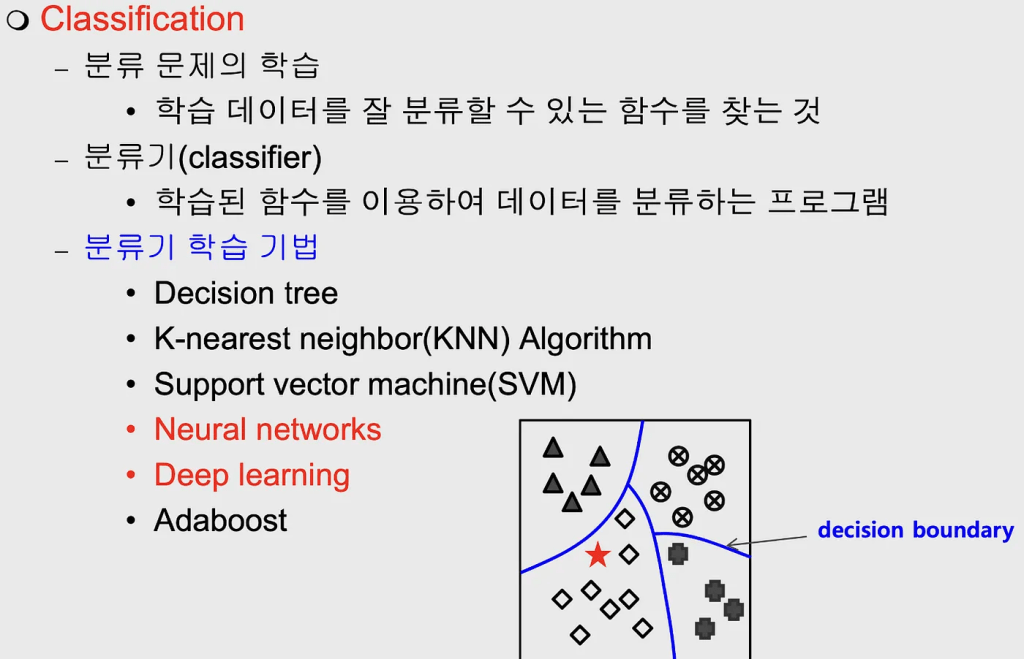
Classification
데이터들을 정해진 몇 개의 class로 대응시키는 문제
Binary classification
데이터를 2가지 class로 분류함
공부한 시간을 기준으로 성적이 pass했는지 non-pass 했는지를 예측하는 시스템
Multi-label classification
데이터를 여러 가지 class로 분류함
공부한 시간을 기반으로 성적이 A,B,C,D,F 이지를 예측하는 시스템
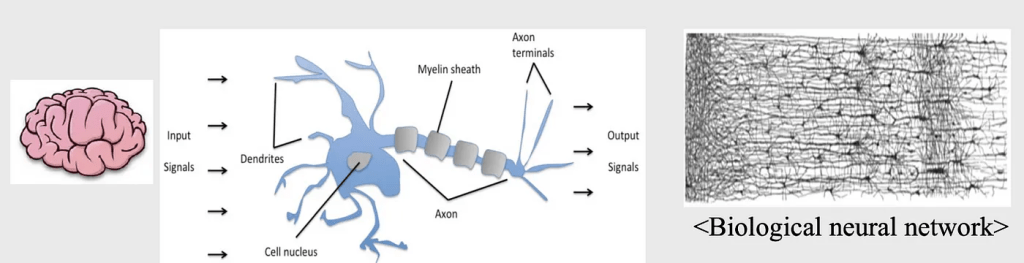
신경망
인간 두뇌의 생리적 활동에 대한 계산적 모델을 통해 인공지능을 구현하려는 분야
인간의 궁극적인 꿈 : 생각하는 기계 만들기
생물학적인 뉴런의 구성도
여러 개의 Signals 들이 입력되어서 cell nucleus에서 합해짐
합쳐진 시그널들이 일정한 값 이상이 될 때에는 활성화가 되어서 다음 뉴런에 전달됨
Biological neuron 동작 원리를 흉내냄
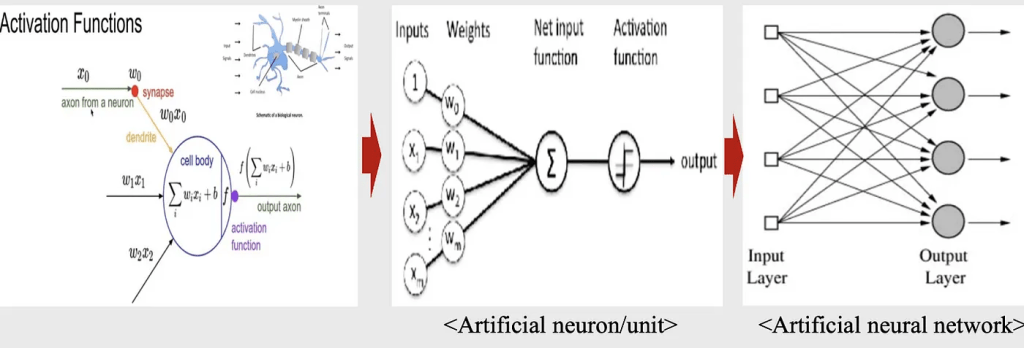
인공적인 뉴런을 만듦
인공적인 뉴럴 네트워크
인공적인 뉴런을 여러 개 결합한 것
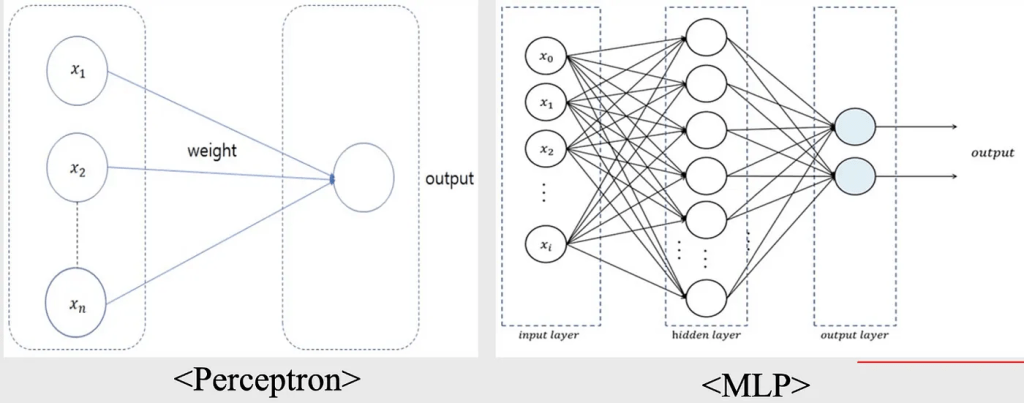
perceptron
입력 노드와 출력 노드로 구성된 ANN
Frank Rosenblatte 박사에 의해 고안됨
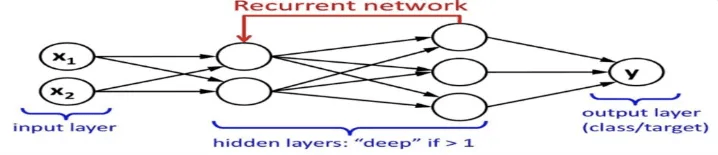
Multi-layer perceptron (MLP)
input layer 및 output layer와 함께 hidden layer가 존재함
Marvin Minsky 교수에 의해 고안됨
Deep neural network (DNN)
은닉층이 2개 이상인 MLP를 의미
딥러닝(deep learning.)
Deep NN을 사용해 만든 모든 알고리즘
딥러닝의 종류.
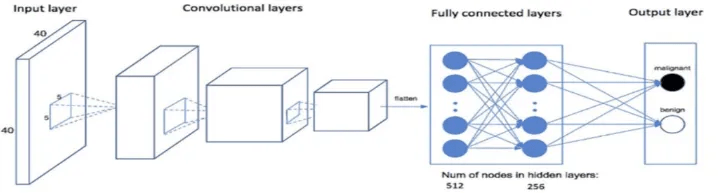
Convolutional neural network (CNN)
Recurrent Neural network(RNN)
Restricted Boltzmann Machine (RBM)
Deep Belief Network (DBN)
Generative Adversarial Network (GAN)
Relation Networks (RN)
Convolutional neural network (CNN)
특징맵을 생성하는 필터까지도 학습이 가능해 비전(vision)분야에서 성능이 우수함
Recurrent Neural network (RNN)
음성과 같은 Time-series data의 처리에 적합함
필요한 개발 툴.
IDE : jupyter Notebook
Python
Numpy : 강력한 계산 기능 수행
Matplotlib : 분석된 데이터의 시각화
Scikit-Learn : Python의 ML package
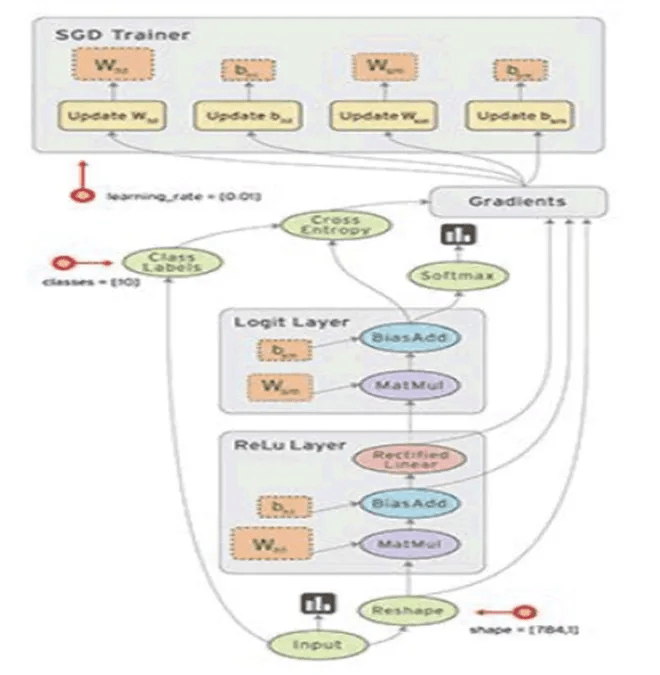
TensorFlow
머신러닝을 위해 구글에서 만들어짐
data flows를 사용해서 수치 계산을 위한 open-source software library for
최근에 머신러닝 라이브러리로 가장 많이 사용 되고 있음
머신러닝으로 암 데이터 예측.
특징 데이터
Age와 tumor_size
Label 데이터
0(암), 1(정상)
학습 모델
Multi-variable linear
regression model
ML library
Scikit-learn 사용함
import matplotlib.pyplot as plt
import numpy as np
import numpy.random as npr
from sklearn import datasets, linear_model
from sklearn.metrics import mean_squared_error, r2_score
datum = np.genfromtxt('../Desktop/data/cancer_data.csv',delimiter = ',', dtype = np.float32, skip_header = True)
# except header.
datum = datum[1:,:]
#shuffle.
npr.shuffle(datum)
X = datum[:, :2]
Y = datum[:, 2]
train_x = X[:60]
test_x = X[60:80]
val_x = X[80:]
train_y = Y[:60]
test_y = Y[60:80]
val_y = Y[80:]
regr = linear_model.LinearRegression()
regr.fit(train_x, train_y)
test_preds = regr.predict(test_x)
fig = plt.figure()
ax = fig.add_subplot(2,2,1)
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.set_title('Pred')
test_preds = [0 if pred <= 0.5 else 1 for pred in test_preds]
pred_colors = ['b' if pred == 0 else 'r' for pred in test_preds]
ax.scatter(test_x[:,0], test_x[:,1], color = pred_colors, linewidth = 3)
ax = fig.add_subplot(2,2,2)
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.set_title('True')
y_colors = ['b' if y == 0 else 'r' for y in test_y]
ax.scatter(test_x[:,0], test_x[:,1], color = y_colors, linewidth = 3)
plt.show()